

Delivery time prediction has long been a part of city logistics, but refining accuracy has recently become very important for services such as Deliveroo, Foodpanda and Uber Eats which deliver food on demand.
These services must receive an order and have it delivered within 30 minutes to appease their users. In these situations +/- five minutes can make a big difference so, for customer satisfaction, it’s important that the initial prediction is accurate and that any delays are communicated effectively.
In this article, I’ll discuss my experience building a real-world delivery time prediction model for a food delivery startup and how it came to give better predictions than our trained operations team. I’ll touch on the technical topics of machine learning while focusing on the business knowledge required to create a well-functioning predictive model.
Food Delivery Time Prediction Roadmap
- Problem Statement
- The Data
- Toolkit
- Model Building
- Improving Estimates
Problem Statement
To start, let’s formulate a problem statement we can work with. This will help us to stay focused on the goal.
We’d like to build a model which will take data about food delivery as input and then output the desired pick-up time to be communicated to drivers.
Some other things to note:
- The deliveries are large. We can assume they require cars.
- The supplier (or suppliers) range from restaurants to caterers and can have very different characteristics.
- Let’s assume drivers arrive at the supplier at exactly the dictated pick-up time. In reality this isn’t always true, but with a sufficient number of drivers, aberrations can be kept to a minimal amount.
- Food should not be delivered too late as the customer will be left waiting and angry; nor can it arrive too early as it will have to sit out before the customer is ready to eat it.
The Data
As an input to our model, we have three categories of data that are typical for this sort of problem:
- Orders: What are people ordering? What supplier are they ordering from? What time is the delivery?
- Customers: Who is ordering? Where are they located?
- Delivery Results: For previous deliveries, how did we perform? How long did each step take?
An example of the data available for a delivery is:
Delivery Team : Deliveries 'R' Us
Order_ID : 12345
Agent_Name : Bob Driver
Supplier : Delicious Donuts
Customer : Big Corporation Inc.
Pickup_Address : Shop 1, Busy Street, 23456, Hong Kong
Delivery_Address : Level 9, Skyscraper, 34567, Hong Kong
Delivery_Time : 29/05/2016 08:00:00
Order_Size : $500Since we have a lot of text, we’ll need to process the data first to get it in a machine-ready format.
The addresses can be processed using regular expressions to get more structured information. The key points are: floor, building, postal code, area and country.
After the processing above, the building, areas and postal codes can be combined with the other variables to perform one-hot encoding. One-hot encoding will create many binary variables for each possible text. We can then feed these numeric variables into our models.
Training
To train the model we’ll use data from previous deliveries, including the predicted time for delivery and the actual time for delivery (the target variable for our exercise). For the purpose of this article, we will work with around 1000 data points.
Toolkit
Before going any further, we should consider what models will be best to solve the type of problem we have. The diagram below from the scikit-learn documentation gives a great way to decide which algorithm you should use.
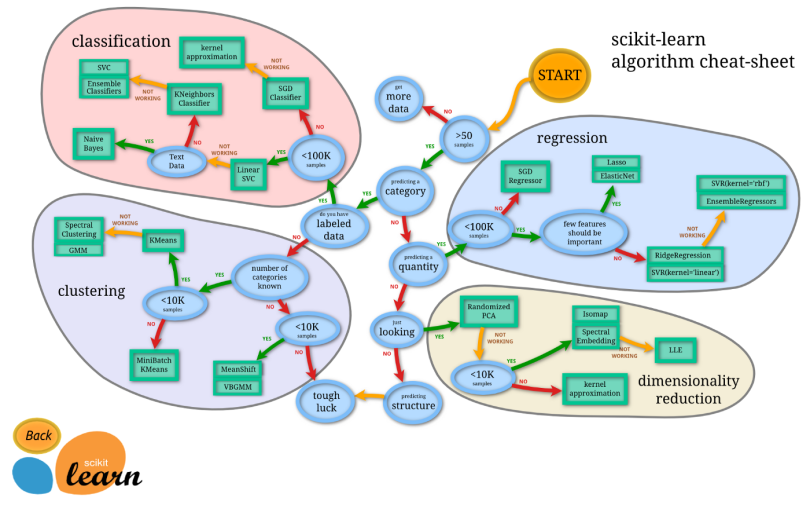
Let’s have a look at what we know about our problem:
- As previously mentioned, we have 1000+ data points for training.
- The output of the model should be a numeric value.
- Due to the one-hot encoding, we’re left with a fairly large number of binary variables which means it’s likely that many features are important.
With this in mind, we can follow along the chart above to arrive at ridge regression and SVR with a linear kernel. For the sake of simplicity, we’ll just work with ridge regression as well as add a random forest regressor to see how it performs differently with the data.
If you’re interested in some more background, you can read up on the algorithms on their respective pages in the scikit-learn documentation: ridge regression, SVR (support vector regression) and random forest regression.
Performance Metrics
We should also pay attention to the metric that we’ll use to judge our model’s effectiveness.
A common metric to get a quick idea of our performance is the mean absolute error (MAE). This tells us the average of the difference between our delivery time estimates and the actual delivery time.
We can then define two more domain-specific metrics:
- Basically on-time (< five minutes late)
- OK, we’re a little late (< 10 minutes late)
These two metrics tell us how often we’ll upset users. If we’re 15 minutes late or 25 minutes late, it doesn’t really matter to the user, we’re just really late. MAE doesn’t realize this, and will count one worse than the other but in terms of the business, it’s effectively the same thing and it’s important our model understands that.
Note: We’ll actually use the inverse of these metrics (i.e. deliveries over five minutes late) as they are a little easier to work with.
So a quick recap: We know what we need to do, we know what data we have to do it with and we know the way we’re going to do it — so let’s get doing!
Model Building
Let’s think about what is involved in food delivery. We can break it down into three principal components:
- Pick up the food from the supplier.
- Drive from the supplier to the customer.
- Drop off the food to the customer.
We can predict the time taken for each component and then add these together to get the final delivery time.
Delivery Time = Pick-up Time + Point-to-Point Time + Drop-off Time
Alternatively, we could train a model to predict the entire delivery time. The reason we should break this up is to create specialty models which will have superior ability over one generic model. If we think about the models as people it makes sense. In your business development team you would have a person who knows the suppliers really well and how long they might take for delivery. In your client service team you would have someone who knows each client well and can predict how long the delivery might take based on their location and building. We’re structuring our process with this in mind.
Now that we have three stages, let’s dive into them and build our models.
Supplier Pick-Up
When a driver arrives at a destination, he is required to find a parking spot, pick-up the food and make it back to the car. Let’s explore the potential complications that could occur during this process.
- No parking: For restaurants located in the city center this can be significantly more difficult compared to those located in more residential areas. To capture this information we can use the zip code or the latitude/longitude information. I found that postal codes were particularly valuable since they capture high-level generic information due to their specific structure.
- Difficult access: Restaurants will tend to be fairly easy to access since they rely on that to serve customers, but caterers can be in industrial areas without an obvious entrance, which makes it more difficult for drivers. We can likewise use location information while adding the category of the supplier.
- Food not ready: As the order sizes can be quite large, it’s not uncommon for food to be unprepared. To deal with this the caterer can be contacted on the day of the pick-up to make sure the food will be ready on time. The response to these messages would be a useful way to understand our timing. Whether or not the particular supplier has a history would also be useful input. Finally, the order size is a good indicator; not much can go wrong when preparing a small amount of food but when you’re feeding 100 people there’s a lot more potential for something to go wrong.
- Something missing from the order: Driver should check the order on arrival and in some cases they may find something missing. This means they must wait for the extra food to be prepared. Again, this probably depends on the supplier and how busy they are at the time of pick-up.
For this part of the problem we’ll use the following data points:
Supplier : Delicious Donuts
Customer : Big Corporation Inc.
Pickup_Address : Shop 1, Busy Street, 23456, Hong Kong
Delivery_Time : 29/05/2016 08:00:00
Order_Size : $500After performing the processing as described above, we can then feed the data into our scikit-learn models, resulting in the following:
Baseline Results:
Mean Absolute Error: 544 seconds
Greater than 5 mins late: 55%
Greater than 10 mins late: 19%
Random Forest Results:
Mean Absolute Error: 575 seconds
Greater than 5 mins late: 42%
Greater than 10 mins late: 22%
Linear Regressor Results:
Mean Absolute Error: 550 seconds
Greater than 5 mins late: 44%
Greater than 10 mins late: 17%
Ensemble Results:
Mean Absolute Error: 549 seconds
Greater than 5 mins late: 45%
Greater than 10 mins late: 17%
You can see that if we use the basic metric of mean absolute error (MAE), all of the models perform worse than the baseline model. However, if we look at the metrics, which are more relevant to the food delivery business, we see that each model has its benefits.
The random forest model reduces the orders greater than five minutes late by almost 25 percent. The Linear Regressor does best in reducing the orders which are 10 minutes late, by around 10 percent. Interestingly, the ensemble model does fairly well in both metrics but notably, it has the smallest MAE out of the three models.
When choosing the correct model, the business goals come first, dictating our choice of important metrics and thus, correct model. With this motivation, we’ll stick with the ensemble model.
Point-to-Point
Estimating the travel time between destinations is a tricky task for many reasons; there are thousands of routes to choose from, traffic conditions that are constantly changing, road closures and accidents; all of which provide nothing but unpredictability for any model you create.
Luckily for us, there’s a company that’s thought long and hard about this problem and has collected millions of data points to help better understand the environment. Maybe you’ve heard of it?

To predict point-to-point travel time we will call the Google Maps API with the known pick-up and drop-off points. The results returned include parameters taking into account traffic and worse-case-scenarios, which can be used as input to the model. A call to the API is quite simple, it looks like this:
gmaps = googlemaps.Client(key='MY_API_KEY')
params = {'mode': 'driving',
'alternatives': False,
'avoid': 'tolls',
'language': 'en',
'units': 'metric',
'region': country}
directions_result = gmaps.directions(pick_up_location,
drop_off_location,
arrival_time=arrival_time,
**params)
With this, we can get a highly accurate result for a problem that has already been well thought-through.
Before implementing this model, our organization was using the public Google Maps interface to predict the delivery times so the performance of our new model for this part of the journey is identical to the baseline. As such, we won’t calculate any comparisons here.
An important side-note is that addresses aren’t always properly formatted! When querying Google Maps there’s always a chance that they’ll respond saying “Uh…I don’t know,” to which we must have an answer. This is a great example of how humans and machines must work together. Whenever an address isn’t properly formed it’s possible for an operator to step in and clarify the address or even call up the customer to clarify the information.
With that, we can move on the third part of our model.
Customer Drop-Off
Once the driver arrives at the location they must find parking, get the food to the right person and get a final sign-off. Potential issues along the way include:
- Parking garage has height restrictions: It’s simple, but many deliveries happen in vans and in this case, there may be height restrictions stopping drivers from using the main entrance.
- Building has no parking: This is an obvious one. No parking means that the driver has to dedicate time driving around and looking for somewhere to leave his vehicle while doing the delivery — or even risk parking illegally to make the delivery.
- Building security issue: Most modern office buildings require a security card to gain access. In the best case, drivers can simply be swiped through, but if worse comes to worst, drivers can be required to go to a separate location, sign-up for a card and then use a back entrance.
- Customer on a high floor or in a tricky location: It may sound ridiculous but some office buildings are very difficult to navigate with different elevators for different floors. For smaller companies, they can be hidden among a maze of hallways.
With all of these, postal code is a great indicator because it tells us if we can expect a business district or a residential area. We can also deep-dive further on the address. For example, if we have floor 40 it’s quite obvious the delivery is in a big tower block and will likely have a complicated security process.
For this part of the problem we’ll use the following data points.
Customer : Big Corporation Inc.
Delivery_Address : Level 9, Skyscraper, 34567, Hong Kong
Delivery_Time : 29/05/2016 08:00:00
Order_Size : $500
After performing the typical processing and running our models we see the following:
Baseline Results:
Mean Absolute Error: 351 seconds
Greater than 5 mins late: 35%
Greater than 10 mins late: 0%
Random Forest Results:
Mean Absolute Error: 296 seconds
Greater than 5 mins late: 15%
Greater than 10 mins late: 7%
Linear Regressor Results:
Mean Absolute Error: 300 seconds
Greater than 5 mins late: 14%
Greater than 10 mins late: 5%
Ensemble Results:
Mean Absolute Error: 293 seconds
Greater than 5 mins late: 13%
Greater than 10 mins late: 6%
Here, we’re able to see a reduction in MAE of 17 percent — much better than before. Similarly, we see reductions in the orders greater than five minutes late by a humongous 63 percent. On the other hand, the model does increase the number of orders late from zero percent to six percent. Again, we’re faced with a trade-off between models which both have their merits and we must let our business KPIs be the deciding factors.
Putting It All Together
We can now combine our models together with the following formula:
Delivery Time = Pick-up Time + Point-to-Point Time + Drop-off Time + Hyper-parameter
Note the addition of a hyperparameter this time. We’ll add this in to take into account any other weird effects that we see in the data such as the pick-up time always being set five minutes earlier to meet the expectations of drivers. We’ll set this parameter in order to minimize the final error metrics after calculating the combined results.
Putting it all together, we get the final result:
Baseline Results:
Mean Absolute Error: 1429 seconds
Greater than 5 mins late: 60%
Greater than 10 mins late: 19%
Ensemble Results:
Mean Absolute Error: 1263 seconds
Greater than 5 mins late: 41%
Greater than 10 mins late: 12%
So our final model has a significant improvement over the baseline model in all metrics; we did it!
Most importantly, we’ve seen a reduction in orders greater than 10 minutes late — almost 40 percent! We were able to achieve this by working on three separate models which were optimized to their own specific business problem. Combining the models and fine-tuning at the last stage helps ensure we produced a model that is on the level of trained professionals.
Improving Estimates
Having a model which gives even more accuracy would be great, but it would also require a lot more effort due to the law of diminishing returns. Instead, there are other solutions if we think more about the business case and less about machine learning.
Lateness vs. Earliness
As you may recall from the start, this model is for catering delivery, which means we know the delivery time in advance. One simple way to avoid late deliveries is to take whatever value the model outputs and increase it to make sure we’re early enough.
This is not a great solution because being too early is also a problem. The food could go bad or be unprepared. However, it does bring up the point that we should consider the distribution of lateness and earliness. Maybe it’s better if we’re 10 minutes early than if we’re five minutes late. With the metrics used up until this point, we didn’t optimize for such scenarios and so we can reconsider this and adjust accordingly.
Delivery Windows
Another thing to consider is how the model is presented to users. If a user is told you’ll arrive at 2 p.m. and you don’t, they’ll be frustrated. If you tell someone you’ll be there between 1:45 p.m.and 2 p.m. then you can aim to deliver at 1:50pm and if you’re a little late you have leeway.
It’s always important to consider machine learning problems as a solution to an actual real-world problem, otherwise you might be developing so-called improvements that would otherwise be impossible from the model itself.
Supplier Feedback
One of the key wins for this model was effectively differentiating between the suppliers’ different preparation times. This tells us that the suppliers must have very different performance.
Digging deeper into the data, we found that drivers were spending three times as many minutes at a few suppliers. With this information, we could talk with the suppliers and identify the problems to ultimately reduce the time drivers spend at these suppliers. By reducing the variation, we improve the overall performance of the model.
Not only did we break down our problem into three components to build targeted models and create a fully-functioning predictive model, we used our business knowledge to improve the effectiveness of our model.
This resulted in a 40 percent reduction in orders that were over 10 minutes late. This kind of progress translates directly into dollars saved in refunds. The model also helped lighten the load on the operations team which let them focus on more meaningful tasks such as improving supplier efficiencies.
This is the general procedure that you can use to apply machine learning to solve business problems. It’s an approach that makes sure to get the foundation right before optimizing for the extra few percentage points of improvement. It’s a methodology I’ve used successfully and I hope you can too.


