

I’ve written previously about random forest regression, so now it’s time to dig deeper with random forest classifier. Let’s jump into ensemble learning and how to implement it using Python. If you’d like to follow along with the tutorial, make sure to pull up the code.
What Is Random Forest Classifier?
Random forest classifier is an ensemble tree-based machine learning algorithm. The random forest classifier is a set of decision trees from a randomly selected subset of the training set. It aggregates the votes from different decision trees to decide the final class of the test object.
What Are Ensemble Algorithms?
Ensemble algorithms are those which combine more than one algorithm of the same or different kind for classifying objects. For example, running a prediction over naive Bayes, SVM and decision tree and then taking a vote for final consideration of class for the test object.
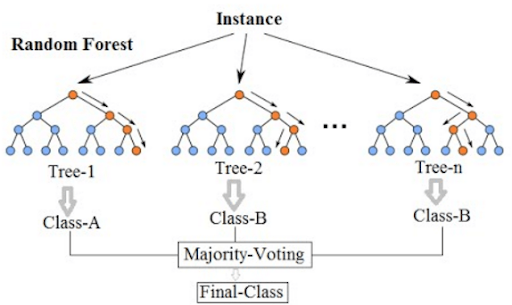
Types of Random Forest Classifier Models
1. Random forest classifier prediction for a classification problem:
f(x) = majority vote of all predicted classes over B trees
2. Random forest classifier prediction for a regression problem:
f(x) = sum of all subtree predictions divided over B trees
Random Forest Classifier Example
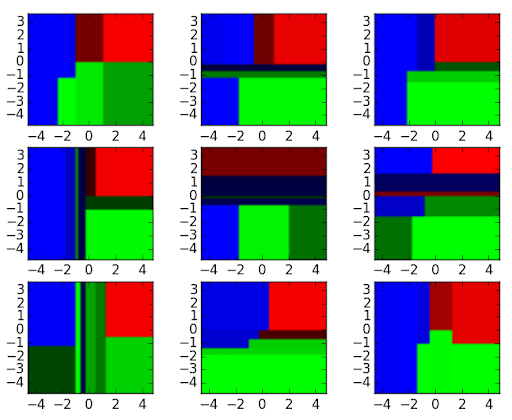
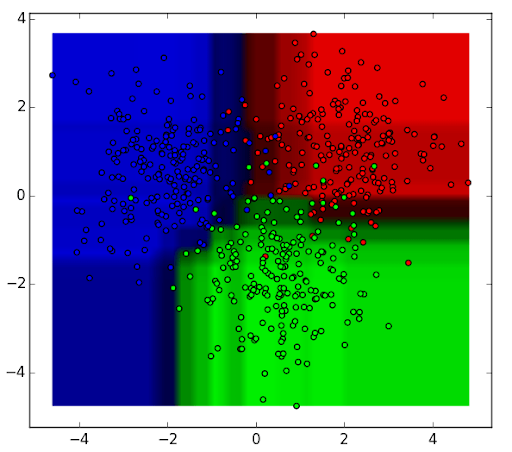
We can aggregate the nine decision tree classifiers shown above into a random forest ensemble which combines their input (on the right). You can think of the horizontal and vertical axes of the above decision tree outputs as features x1 and x2. At certain values of each feature, the decision tree outputs a classification of blue, green, red, etc.
The above results are aggregated, through model votes or averaging, into a single ensemble model that ends up outperforming any individual decision tree’s output.
Random Forest Algorithm Advantages
- Random forest is one of the most accurate learning algorithms available. For many data sets, it produces a highly accurate classifier.
- It runs efficiently on large databases.
- It can handle thousands of input variables without variable deletion.
- It gives estimates of what variables are important in the classification.
- It generates an internal unbiased estimate of the generalization error as the forest building progresses.
- It has an effective method for estimating missing data and maintains accuracy when a large proportion of the data are missing.
Random Forest Algorithm Disadvantages
- Random forests have been observed to overfit for some data sets with noisy classification/regression tasks.
- For data including categorical variables with different numbers of levels, random forests are biased in favor of those attributes with more levels. Therefore, the variable importance scores from random forest are not reliable for this type of data.
How to Implement Random Forest Classifier in Python
- Importing Python Libraries and Loading our Data Set into a Data Frame
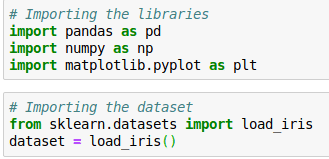
- Splitting our Data Set Into Training Set and Test Set
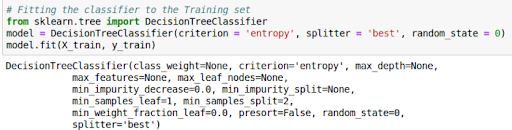
- Creating a Random Forest Regression Model and Fitting it to the Training Data
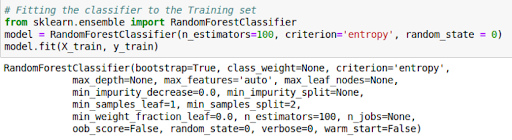
- Predicting the Test Set Results and Making the Confusion Matrix
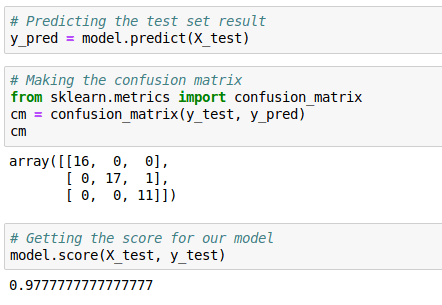
There you have it! Now you know all about the random forest classifier and its implementation using Python. Now it’s time for you to try for yourself. Good luck!


