

Statistics is the science of learning from data. Statistical knowledge aids in the proper methods for collecting data, analyzing data and effectively presenting the results derived from data. These methods are crucial to making decisions and predictions, whether it be predicting the consumer demand for a product, using text mining to filter spam emails or making real-time decisions in self-driving cars.
Bootstrapping Statistics Defined
Bootstrapping statistics is a form of hypothesis testing that involves resampling a single data set to create a multitude of simulated samples. Those samples are used to calculate standard errors, confidence intervals and for hypothesis testing. This approach allows you to generate a more accurate sample from a smaller data set than the traditional method.
Most of the time when you’re conducting research, it’s impractical to collect data from the entire population. This can be due to budget and/or time constraints, among other factors. Instead, a subset of the population is taken and insight is gathered from that subset to learn more about the population.
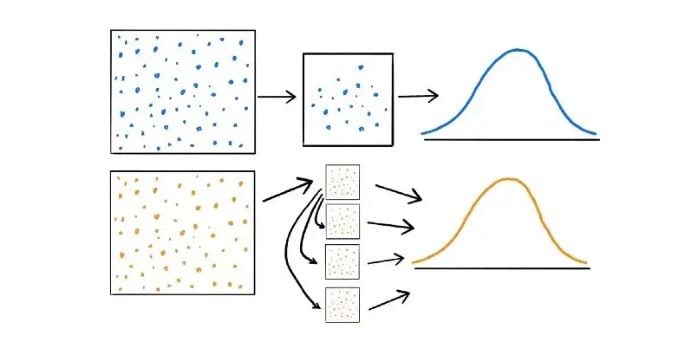
This means that suitably accurate information can be obtained quickly and relatively inexpensively from an appropriately drawn sample. However, many things can affect how well a sample reflects the population, and therefore, the validity and reliability of the conclusions. Because of this, let us talk about bootstrapping statistics.
What Is Bootstrapping Statistics?
“Bootstrapping is a statistical procedure that resamples a single data set to create many simulated samples. This process allows for the calculation of standard errors, confidence intervals, and hypothesis testing,” according to a post on bootstrapping statistics from statistician Jim Frost.
A bootstrapping approach is an extremely useful alternative to the traditional method of hypothesis testing, as it’s fairly simple and it mitigates some of the pitfalls encountered within the traditional approach.
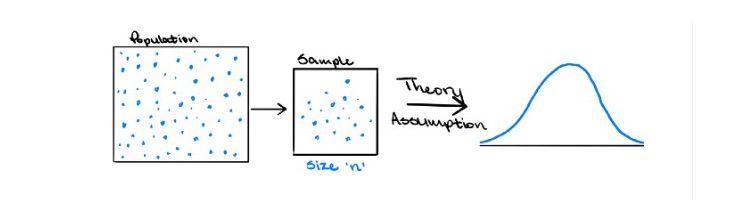
Statistical inference generally relies on the sampling distribution and the standard error of the feature of interest. The traditional approach, or large sample approach, draws one sample of size n from the population, and that sample is used to calculate population estimates to then make inferences on. In reality, only one sample has been observed.
However, a sampling distribution is a theoretical set of all possible estimates if the population were to be resampled. The theory states that, under certain conditions such as large sample sizes, the sampling distribution will be approximately normal, and the standard deviation of the distribution will be equal to the standard error. But what happens if the sample size is not sufficiently large enough? Then, it can’t necessarily be assumed that the theoretical sampling distribution is normal. This makes it difficult to determine the standard error of the estimate and harder to draw reasonable conclusions from the data.
How Bootstrapping Statistics Works
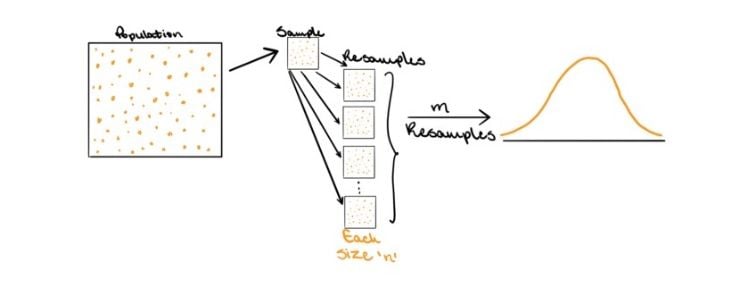
In the bootstrapping approach, a sample of size n is drawn from the population. Let’s call this sample S. Then, rather than using theory to determine all possible estimates, the sampling distribution is created by resampling observations with replacement from S m times, with each resampled set having n observations. Now, if sampled appropriately, S should be representative of the population. Therefore, by resampling S m times with replacement, it would be as if m samples were drawn from the original population, and the estimates derived would be representative of the theoretical distribution under the traditional approach.
Increasing the number of resamples, m, will not increase the amount of information in the data. That is, resampling the original set 100,000 times is not more useful than resampling it 1,000 times. The amount of information within the set is dependent on the sample size, n, which will remain constant throughout each resample. The benefit of more resamples, then, is to derive a better estimate of the sampling distribution.
Resampling in Bootstrap Statistics
Resampling is the process of taking a sample and using it to produce simulated samples for more accurate calculations. To better understand what this means, consider these basic principles:
- Each data point in the original sample has an equal chance of being chosen and resampled into a simulated sample.
- Because data points are returned to the original sample after being selected, a data point may be chosen more than once for the same simulated sample.
- Each resampled, or simulated, sample is the same size as the original sample.
Keep in mind that it’s often best to create at least 1,000 simulated samples for bootstrapping to work properly.
Applications of the Bootstrapping Method
Training Machine Learning Algorithms
Machine learning algorithms can be trained with an initial sample. Bootstrapping adds another dimension to this process by resampling this initial sample to produce simulated samples, which algorithms are exposed to post-training. This process provides a clearer picture as to how machine learning algorithms perform outside of training.
Testing Hypotheses
Traditional statistical methods often try to make generalizations about a data set based on a single sample. By gleaning insights from thousands of simulated samples, the bootstrapping method makes it possible to determine more accurate calculations.
Creating Confidence Intervals
When calculating a statistic of interest, bootstrapping can generate thousands of simulated samples that each feature their own statistic of interest. Teams can then develop a confidence interval that is more precise since it relies on a larger collection of samples as opposed to just one sample or a few samples.
Calculating Standard Error
Bootstrapping is more equipped than traditional methods for calculating standard error since it generates many simulated samples at random. This makes it easier to determine the means of different samples and estimate a sampling distribution that is more reflective of the larger data set and can be used to find the standard error.
Advantages of Bootstrapping Statistics
“The advantages of bootstrapping are that it is a straightforward way to derive the estimates of standard errors and confidence intervals, and it is convenient since it avoids the cost of repeating the experiment to get other groups of sampled data. Although it is impossible to know the true confidence interval for most problems, bootstrapping is asymptotically consistent and more accurate than using the standard intervals obtained using sample variance and the assumption of normality,” according to author Graysen Cline in their book, Nonparametric Statistical Methods Using R.
Now that we understand the bootstrapping approach, it must be noted that the results derived are basically identical to those of the traditional approach. Additionally, the bootstrapping approach will always work because it doesn’t assume any underlying distribution of the data.
This contrasts with the traditional approach which theoretically assumes that the data are normally distributed. Knowing how the bootstrapping approach works, you might wonder, does the bootstrapping approach rely too much on the observed data? This is a good question, given that the resamples are derived from the initial sample. And because of this, it’s logical to assume that an outlier will skew the estimates from the resamples.
While this is true, if the traditional approach is considered, an outlier within the data set will also skew the mean and inflate the standard error of the estimate. While it might be tempting to think that an outlier can show up multiple times within the resampled data and skew the results and thus, making the traditional approach better, the bootstrapping approach relies as much on the data as the traditional approach.
Both approaches require the use of appropriately drawn samples to make inferences about populations. However, the biggest difference between these two methods is the mechanics behind estimating the sampling distribution. The traditional procedure requires one to have a test statistic that satisfies particular assumptions in order to achieve valid results, and this is largely dependent on the experimental design. The traditional approach also uses theory to tell what the sampling distribution should look like, but the results fall apart if the assumptions of the theory are not met.
The bootstrapping method, on the other hand, takes the original sample data and then resamples it to create many [simulated] samples. This approach doesn’t rely on theory since the sampling distribution can be observed, and you don’t have to worry about any assumptions. This technique allows for accurate estimates of statistics, which is crucial when using data to make decisions.
Limitations of Bootstrapping Statistics
Bootstrapping offers many benefits compared to traditional statistical methods, but there are some downsides to consider:
- Time-consuming: Thousands of simulated samples are needed for bootstrapping to be accurate.
- Computationally taxing: Because bootstrapping requires thousands of samples and takes longer to complete, it also demands higher levels of computational power.
- Incompatible at times: Bootstrapping isn’t always the best fit for a situation, especially when dealing with spatial data or a time series.
- Prone to bias: Bootstrapping doesn’t always take into account the variability of distributions, leading to errors and biases when making calculations.
Frequently Asked Questions
What is the purpose of bootstrapping statistics?
The purpose of bootstrapping statistics is to give teams an easy, cost-effective way to test hypotheses and make accurate calculations, even when they have limited data to start.
What is the difference between bootstrapping and traditional statistical methods?
Traditional statistics only takes one sample from a population and uses that sample to draw estimates for the larger population. However, bootstrapping takes one sample and resamples it to generate many samples, making calculations about the larger population based on the sampling distribution of these simulated samples.
What is a good sample size for bootstrapping?
It’s best to aim for resampling a sample to produce at least 1,000 simulated samples.
What is the difference between bootstrapping and sampling?
Bootstrapping involves resampling an existing sample to create multiple new simulated samples of a population. Sampling traditionally involves only taking one sample (or smaller group of data) from a larger population, and can be performed in different types of ways (simple random sampling, cluster sampling, etc.).


