

Keras is an open-source, user-friendly deep learning library created by Francois Chollet, a deep learning researcher at Google. The user-friendly design principles behind Keras makes it easy for users to turn code into a product quickly. As a result, it has many applications in both industry and academia.
The Keras team’s mission is to democratize machine learning. This means it was designed with specific standards that aim to make it productive, reliable, and accessible to a large audience. In this post, I want to explore key features of Keras (as outlined in the Keras Documentation) to answer the question of why Keras is the leading deep learning toolkit. In particular, I will discuss three focal features of Keras: user-friendly design, easy deployment across many platforms, and scalability.
User-Friendly Design
Keras has simple-to-use modules for virtually every facet of the neural network model building process, including the model, layer, callback, optimizer, and loss methods. These easy-to-use functions enable rapid model training, robust model testing, fast experimentation, and flexible deployment, among many other functionalities.
The model API contains the sequential model class (limited to single-input, single-output stacks of layers), the model class (enables arbitrary model architectures), model training methods (for fit, compile, and evaluate), and model saving methods. These model methods allow you to easily augment model objects with model parameter details such as loss functions, layers, nodes, optimizers and activation functions. Further, it allows you to call fit and predict methods on instantiated model objects in an intuitive and easy-to-read manner.
For example, a convolutional neural network that is typically used for image recognition can be initiated, layered, trained and tested in 12 simple lines of code:

Another example is implementing an LSTM model, which can be used for speech recognition tasks. The system can do this with six lines of code:
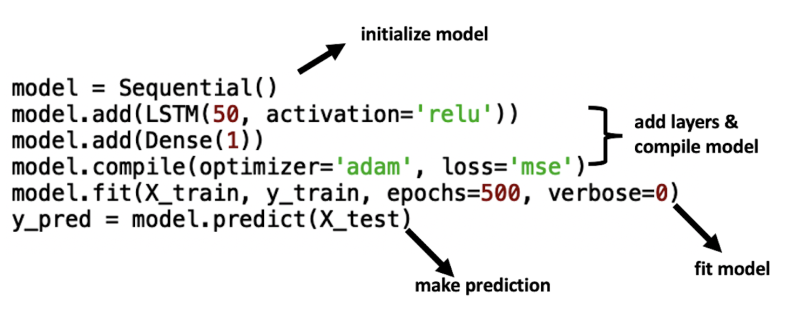
The model methods also allow you to save and reload model weights, which averts the time consuming task of repeatedly retraining your models on the same data.
The layers methods enables easy addition of layers, which are the building blocks of neural networks. To see this, take the examples of adding convolutional and LSTM layers shown above. To add a convolutional layer, you simply call the ‘add()’ method on your model object and pass in the Conv2D method as an argument:
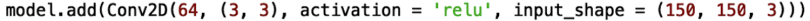
To add an LSTM layer, you call the ‘add()’ method on you model object and pass in the LSTM method:
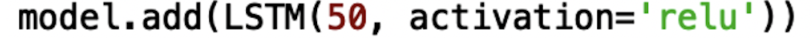
Overall, the layers methods contain dense layers commonly used across various neural network architectures, LSTMs layers, convolutional and pooling layers for convolutional neural networks, recurrent neural networks layers, among others. It also contains activation layers, normalization layers, and regularization layers. LSTM and recurrent layers can be used to build neural networks used for a variety of prediction tasks involving sequences. These include time series forecasting, speech recognition, grammar learning, sign language translation, and much more. Convolutional neural networks use convolutional layers, from which they get their name. They work on various image classification tasks such as facial recognition and object recognition in self-driving cars. The activation layer API is useful for fast experimentation with activation functions, which mathematically model the neuron firing process in neural network layers. Depending on your use case and the quality of your data, one activation function may be more useful than another. Being able to quickly test several activation functions allows you to quickly generate results and build accurate models faster. For example, if you’d like to try using the rectified linear unit (‘relu’) activation function in your LSTM layer you simply type activation= ‘relu’ in the argument of the LSTM method:
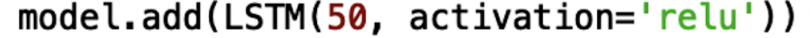
Alternatively, you easily can try the using the hyperbolic tangent activation function by changing very little code:
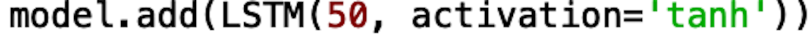
Further, normalization layers help ensure neural network models are trained on positive and negative feature values and have the values impact learning to a similar extent. Finally, regularization layers are useful for preventing overfitting the neural networks.
Keras’ callback methods, which allow users to perform various actions during training, is also particularly useful. For example, the ModelCheckPoint class allows you to save the model weights during training in case of interruption. You can also use this class to pick up where you left off and further fine-tune your model. EarlyStopping allows you to halt training if performance metrics stop improving. In the absence of early stopping, you could lose many hours to training that no longer improves the performance of your model. These callback classes can save hours of training time and computational resources when used correctly.
The optimizer methods allow you to seamlessly implement optimizers like stochastic gradient descent (sgd), Adam, root mean square propagator (RMSProp), AdaDelta, and adagrad. In the case of the new researcher or developer who may not know the theoretical differences between sgd and adam, Keras allows for quickly testing both, leading to faster result generation.
Keras features loss methods for both probabilistic and regression loss, both of which contain easy-to-access suites of loss functions. Given that loss functions advise the training process of the neural networks, being able to run quick experiments with different loss functions enables rapid model development. The network includes binary cross entropy and sparse categorical cross entropy, two popular loss functions for classification. For regression, the loss API includes mean squared error, mean absolute error, mean absolute percentage error, and much more. In the case of both regression and classification tasks, easy access to this suite of functions enables rapid prototyping and experimentation.
Overall, simple-to-use APIs for neural network components allow for easy experimentation, faster results, efficient research, and facile product deployment. All these features mean that Keras lets you design highly customizable workflows that make it easy to quickly go from idea to product.
Research and Industry
Keras is widely used across research institutions and industry, presumably due to its user-friendly nature, which enables efficient research and prototyping. For example, domain experts in research and industry with minimal programming and deep learning knowledge can use Keras to quickly build and optimize models for their use cases.
In the context of research, large institutions like CERN and NASA use Keras for a variety of applications. CERN applies pattern recognition via deep learning for tasks like particle tracking — the study of single particle motion within a medium — to track the Higgs boson, for instance. CERN also uses deep learning for a task called jet flavor tagging, which is related to particle identification. NASA uses deep learning for tasks like exoplanet discovery, planetary navigation on the moon, smart robotic astronauts/robonauts, and much more.
Outside of pure research contexts, Keras has proved useful in business as well. Companies like Netflix have used Keras to build recommender systems that predict user preferences given past data. For Netflix, this involves training a neural network on data consisting of movies and shows a viewer has watched in the past and subsequently predicting which new show or movie a user may prefer. Uber also uses deep neural networks to forecast rider demand, estimated time of arrival for pick-ups and drop offs, find rider/driver matches, and other tasks as well. Additionally, Uber Eats uses neural network-based recommender systems to recommend places to eat to users. Other companies, including Yelp, Instacart, Zocdoc, and Square, also use Keras for various applications.
Overall, while it is straightforward for anyone with minimal programming or deep learning experience to get started with Keras, the widespread adoption of Keras across research and industry demonstrates that it is capable of many powerful and practical applications.
Deployment on Platforms
Keras can also easily be deployed across a variety of platforms. For example, models built using Keras can be deployed on a server through Python runtime. Companies like Uber and Netflix use Node.js to deploy many of their deep learning products, such as their recommender systems. Node.js is a JavaScript framework that is particularly useful for JavaScript developers who would like to employ the Keras API for model development without shouldering the burden of learning a new programming language. Further, Keras model products can be deployed on Android, iOS, Raspberry Pi, and more.
The widespread adoption of Keras in both industry and research establishes it as a leading API in the deep learning space. Additionally, because you can deploy Keras across a wide variety of platforms, the API is very flexible. The fact that Keras is relatively platform agnostic means that it can be used in a variety of web and mobile applications. Further, the flexibility and user-friendly nature of Keras lends itself to rapid innovation in software application development, particularly in data-driven industries.
Keras Scalability
Keras is highly scalable since it natively supports the Tensorflow distribution strategy API. This allows you to easily run your models on thousands of CPU or GPU devices. Model distribution can take one of two forms. The first is data parallelism, in which a single model is trained on multiple devices. The second method, model parallelism, involves training different parts of a single model on multiple devices. Keras supports data parallelism for distributed computing, which enables scalable model development. Scalable model development is crucial for optimizing productivity of the model development, minimizing cost of training models, and minimizing human involvement or intervention when resources on a single machine are scarce.
From a product development standpoint, scalability is crucial for the efficiency and quality of your product. Consider the example of the Netflix recommender systems. As Netflix continues to acquire more paid memberships, more people will use the platform, in turn increasing the computational load for training the neural networks used for the recommender systems. As the number of users grows, more data needs to be stored and used in training the neural network models. More users mean more viewed movies and shows. This translates to an increase in the number of types of viewer preference predictions, which will require longer training times on a larger set of data. This is also the case for testing. Robust testing is costly and may require a significant amount of hardware resources. In both cases, scaling through data parallelization may significantly reduce the time and cost of each part of the machine learning pipeline.
Keras is particularly great if you are starting a new business with underlying deep learning technology, since new businesses have the highest growth potential. For your new business, Keras allows you to scale computation through native support of distributed computing. This allows you to maximize productivity of model development and minimize cost of model training/testing as your platform continues to grow.
Conclusions
Keras is a user-friendly toolkit that significantly lowers the barrier to entry in deep learning research and development. The low barrier to entry with Keras is a design principle that the Keras team intentionally baked into it in an effort to democratize machine learning. If neither programming or deep learning expertise is required to build models with Keras, people from different walks of life with different ideas and experiences can easily apply deep learning to problems they are interested in solving. The wide adoption of Keras in industry and research speaks to these efforts as well. For example, if a chemical physicist, with no deep learning experience, wants to apply deep learning to a novel problem in chemistry, they can easily learn how to use Keras and start testing out ideas. Additionally, if a growing retail company that lacks a data science team seeks to use consumer purchase data to predict demand for their product, they can easily get started with Keras. The low cognitive load for users, the scalability and the easy-to-access and understand functions are major features that attract the research teams of large companies, startups and government research organizations. I encourage readers who have not used Keras, or have limited experience with Keras, to learn more about the library and try incorporating it into their work and/or projects.


