

Selenium is a Python library and tool used for automating web browsers to do a number of tasks like web scraping to extract useful data and information.
Selenium Web Scraping Tutorial
- Install and import Selenium.
- Install and access WebDriver
- Access the desired website with the
driver.get()method. - Locate the XPath for the information you’re trying to scrape.
- Apply these steps to different pages and collect it in a dataframe.
Here’s a step-by-step guide on how to use Selenium to web scrape using NBA player salary data from Hoops Hype.
5 Steps to Use Selenium for Web Scraping
Below are the five steps it takes to use Selenium for web scraping, starting with installing the Python tool to scrape the data.
1. Install and Import
Begin by installing Selenium via the command line with the following command:
pip install seleniumOnce installed, you’re ready for the imports.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import pandas as pd2. Install and Access WebDriver
A WebDriver is a vital ingredient to this process. It will automatically open your browser to access your website of choice. This step is different based on which browser you use to explore the internet. I happen to use Google Chrome. Some say Chrome works best with Selenium, but it does also support Edge, Firefox, Safari and Opera.
For Chrome, you first need to download the WebDriver. There are several different download options based on your version of Chrome. To locate what version of Chrome you have, click on the three vertical dots at the top right corner of your browser window, scroll down to help, and select “About Google Chrome.” There you will see your version. I have version 80.0.3987.149, shown in the screenshots below.
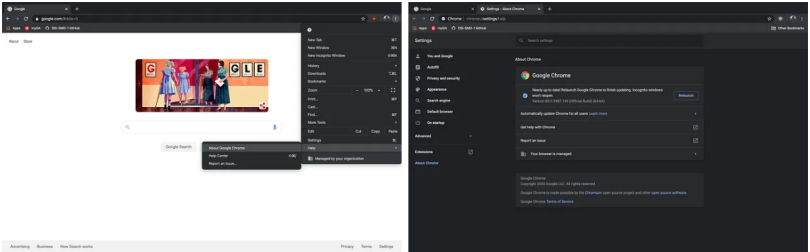
Now, you need to find where you saved your WebDriver download on your local computer. Mine is saved in my default downloads folder. You can now create a driver variable using the direct path of the location of your downloaded WebDriver.
cService = webdriver.ChromeService(executable_path=’C:/Users/MyUsername/Downloads/chromedriver-win64/chromedriver.exe’)
driver = webdriver.Chrome(service=cService)3. Access the Website Via Python
This is a very simple, yet very important step. You need your code to actually open the website you’re attempting to scrape. To do that, we’ll use the driver.get() method:
driver.get('https://hoopshype.com/salaries/players/')When run, this code snippet will open the browser to your desired website.
4. Locate the Specific Information You’re Scraping
In order to extract the information that you’re looking to scrape, you need to locate the element’s XPath. An XPath is a syntax used for finding any element on a webpage. To locate the element’s XPath, highlight the first in the list of what you’re looking for, right click and select inspect. This opens up the developer tools. For my example, I first want to locate the NBA player names, so I select Stephen Curry.
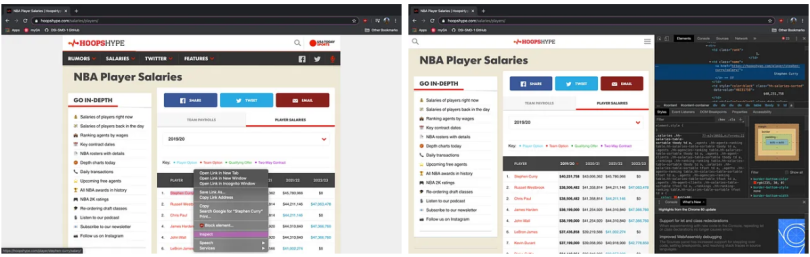
In the developer tools, we now see the element “Stephen Curry” appears as such:
<td class=”name”>
<a href=”https://hoopshype.com/player/stephen-curry/salary/">
Stephen Curry </a>
</td>This element can easily be translated to its XPath, but first, we need to remember that we aren’t just trying to locate this element, but all player names. Using the same process, I located the next element in the list, Russell Westbrook.
<td class=”name”>
<a href=”https://hoopshype.com/player/russell-westbrook/salary/">
Russell Westbrook </a>
</td>The commonality between these two and all other player names is <td class=”name”>, so that is what we will be using to create a list of all player names. Translated into an XPath, it looks like this: //td[@class=”name”]. Breaking that down, all XPaths are preceded by the double slash, which we want in a td tag, with each class in that td tag needing to correspond to “name.” We now can create the list of player names with Selenium’s find_elements method.
players = driver.find_elements(By.XPATH, '//td[@class="name"]')And now to get the text of each player name into a list, we write this function:
players_list = []
for p in range(len(players)):
players_list.append(players[p].text)Following this same process to acquire the player salaries:
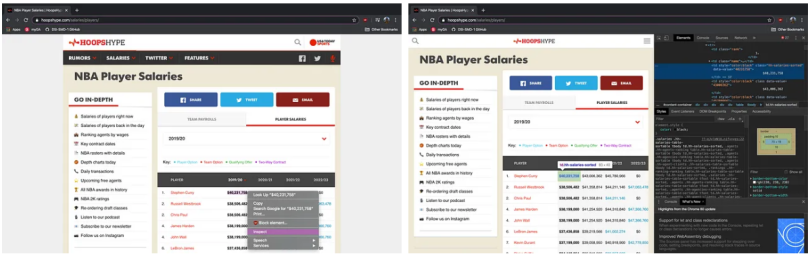
Stephen Curry’s 2019-20 Salary:
<td style=”color:black” class=”hh-salaries-sorted” data-value=”40231758">
$40,231,758 </td>Russel Westbrook’s 2019-20 Salary:
<td style=”color:black” class=”hh-salaries-sorted” data-value=”38506482">
$38,506,482 </td>While inspecting these elements and translating to XPath, we can ignore style and data-value, only worrying about the class.
salaries = driver.find_elements(By.XPATH, '//td[@class="hh-salaries-sorted"]')And the function for the list of salaries text:
salaries_list = []
for s in range(len(salaries)):
salaries_list.append(salaries[s].text)5. Apply to different pages and Tie Everything Together
Often, when using Selenium, you’ll be attempting to retrieve data that is located on multiple different pages from the same website. In my example, hoopshype.com has NBA salary data dating back to the 1990-91 season.
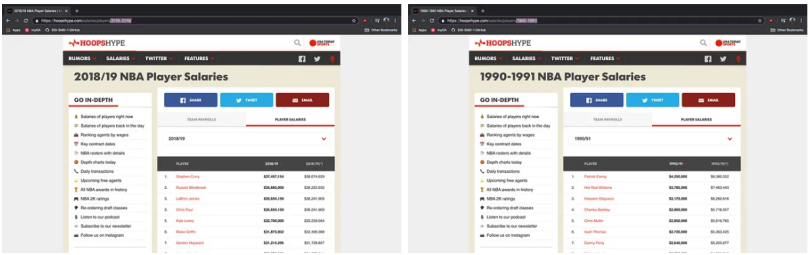
As you can see, the difference between the URL of each season is just a matter of the years being included at the end. So, the URL for the 2018-19 season is: https://hoopshype.com/salaries/players/2018-2019/. And the URL for the 1990-91 season is: https://hoopshype.com/salaries/players/1990-1991/.
With that, we can create a function that loops through every year and accesses each season’s URL and then puts all of the previously shown steps together for each season individually. This function pairs each player with their salary for that season, places them into a temporary dataframe, adds the year onto that temporary dataframe, and then adds this temporary dataframe to a master dataframe that includes all of the data scraped from Hoops Hype. The final code is below!
from selenium.webdriver.common.by import By
import pandas as pd
df = pd.DataFrame(columns=['Player','Salary','Year']) # creates master dataframe
cService = webdriver.ChromeService(executable_path='C:/Users/MyUsername/Downloads/chromedriver-win64/chromedriver.exe') # '/Users/bpfalz/Downloads/chromedriver' for my macbook
driver = webdriver.Chrome(service=cService)
for yr in range(1990,2023):
page_num = str(yr) + '-' + str(yr+1) +'/'
url = 'https://hoopshype.com/salaries/players/' + page_num
driver.get(url)
players = driver.find_elements(By.XPATH, '//td[@class="name"]')
salaries = driver.find_elements(By.XPATH, '//td[@class="hh-salaries-sorted"]')
players_list = []
for p in range(len(players)):
players_list.append(players[p].text)
salaries_list = []
for s in range(len(salaries)):
salaries_list.append(salaries[s].text)
p = int(len(players_list)/2)+1 # marks position of first player in players_list -- first half of list is empty
s = int(len(salaries_list)/2)-1 # marks position of last salary of salaries_list -- second half of list is empty
data_tuples = list(zip(players_list[p:],salaries_list[1:s])) # list of each players name and salary paired together
temp_df = pd.DataFrame(data_tuples, columns=['Player','Salary']) # creates dataframe of each tuple in list
temp_df['Year'] = yr + 1 # adds season ending year to each dataframe
print(temp_df)
df = pd.concat([df, temp_df], ignore_index=True)
driver.close()Frequently Asked Questions
Can Selenium be used for web scraping?
Selenium is a Python library that’s used for automating web browsers to accomplish a number of tasks, including web scraping to extract data.
How do you use Selenium to web scrape?
There are five steps to using Selenium for web scraping:
- Install and import Selenium.
- Install and access the WebDriver.
- Access your chosen website with the
driver.get()method. - Locate the XPath for the information you want to scrape.
- Apply these steps to loop through different pages. Example code looks like this:
from selenium.webdriver.common.by import By
import pandas as pd
df = pd.DataFrame(columns=['Player','Salary','Year']) # creates master dataframe
cService = webdriver.ChromeService(executable_path='C:/Users/MyUsername/Downloads/chromedriver-win64/chromedriver.exe') # '/Users/bpfalz/Downloads/chromedriver' for my macbook
driver = webdriver.Chrome(service=cService)
for yr in range(1990,2023):
page_num = str(yr) + '-' + str(yr+1) +'/'
url = 'https://hoopshype.com/salaries/players/' + page_num
driver.get(url)
players = driver.find_elements(By.XPATH, '//td[@class="name"]')
salaries = driver.find_elements(By.XPATH, '//td[@class="hh-salaries-sorted"]')
players_list = []
for p in range(len(players)):
players_list.append(players[p].text)
salaries_list = []
for s in range(len(salaries)):
salaries_list.append(salaries[s].text)
p = int(len(players_list)/2)+1 # marks position of first player in players_list -- first half of list is empty
s = int(len(salaries_list)/2)-1 # marks position of last salary of salaries_list -- second half of list is empty
data_tuples = list(zip(players_list[p:],salaries_list[1:s])) # list of each players name and salary paired together
temp_df = pd.DataFrame(data_tuples, columns=['Player','Salary']) # creates dataframe of each tuple in list
temp_df['Year'] = yr + 1 # adds season ending year to each dataframe
print(temp_df)
df = pd.concat([df, temp_df], ignore_index=True)
driver.close()

