

If you want to convert a Python list to Pandas DataFrame, there are many options to choose from. You can convert one-dimensional lists, multidimensional lists and more to a Pandas DataFrame either with built-in functions such as zip() and from_records() or by being a bit creative.
How to Convert a List to Pandas DataFrame
There are multiple ways to convert a list to Pandas DataFrame, including:
- Simple Python list to Pandas DatFrame conversion.
- Python zip() method.
- Converting a list of lists to a Pandas DataFrame.
- Converting a dictionary of lists to Pandas DataFrame.
- Converting a list to Pandas DataFrame with from_records().
- Creating a Pandas DataFrame from list with index and column names.
In this article, we’ll cover everything you need to know on how to convert lists to Pandas DataFrame in Python. Regarding library imports, you only need Pandas, so stick this line at the top of your Python script or notebook:
import pandas as pd
6 Methods to Convert a List to Pandas DataFrame
1. Simple Python List to Pandas DataFrame Conversion
Okay, this is an obvious one, and you should use it whenever you want to make a Pandas DataFrame from a list, but the list has to be one-dimensional.
The best way to explain is through an example. The following code snippet declares a list of names and creates a Pandas DataFrame from it:
employees = ["Bob", "Mark", "Jane", "Patrick"]
data = pd.DataFrame(employees)
data
The resulting DataFrame has only one column, and the column name is set to the default range index value:
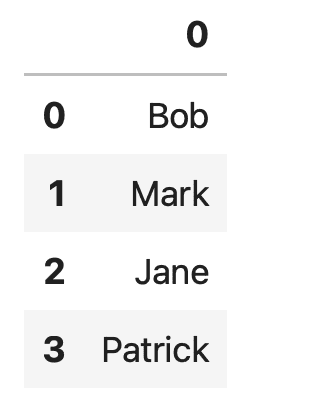
Now, DataFrames that have only one column aren’t particularly interesting, but maybe that’s all you need. If that’s the case, you’ll certainly want to add a column name, so here’s how to do that:
employees = ["Bob", "Mark", "Jane", "Patrick"]
data = pd.DataFrame(employees, columns=["First Name"])
dataThe resulting Pandas DataFrame is a bit easier to understand now:
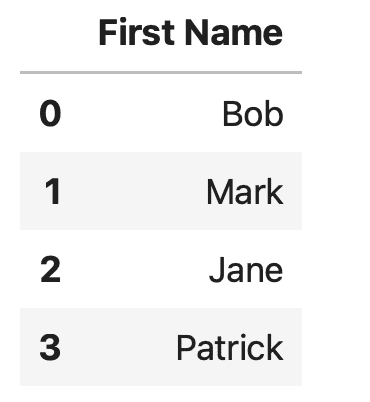
2. Python zip() Method to Convert List to Pandas DataFrame
Python’s zip() function is used to iterate over two or more iterables at the same time. The function takes iterables as arguments and returns an iterator of tuples, which contains the corresponding elements from each iterable.
It goes without saying, but the length of the iterables should be identical. Python won’t raise an exception, but the length of the resulting iterator will be equal to the shortest input iterable.
For example, if list a has 10 elements and list b has only five, then zip() would return an iterable with five elements only.
On the practical side, here’s how to use zip() if you want to know how to add a list to DataFrame. The following code snippet declares two lists and uses zip() to produce a new list which is the combination of corresponding elements. This is a way to go if you want to make a Pandas DataFrame from two lists:
e_first_names = ["Bob", "Mark", "Jane", "Patrick"]
e_last_names = ["Doe", "Markson", "Swift", "Johnson"]
data = pd.DataFrame(
data=list(zip(e_first_names, e_last_names)),
columns=["First Name", "Last Name"]
)
data
When wrapped into a Pandas DataFrame, this means each list will be a dedicated column:
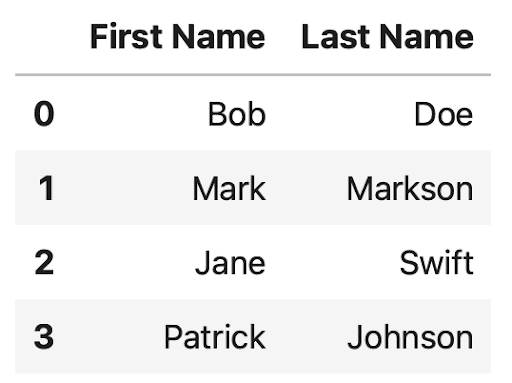
But what if you have more than two lists? Well, zip() can take as many iterables as you want, meaning you can simply stick in the third one:
e_first_names = ["Bob", "Mark", "Jane", "Patrick"]
e_last_names = ["Doe", "Markson", "Swift", "Johnson"]
e_emails = ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
data = pd.DataFrame(
data=list(zip(e_first_names, e_last_names, e_emails)),
columns=["First Name", "Last Name", "Email"]
)
data
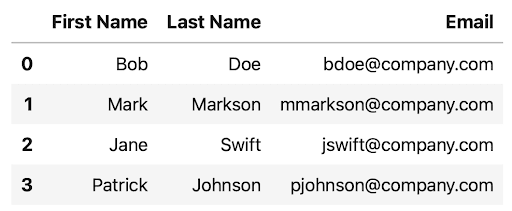
The resulting DataFrame also contains email information now:

Using zip() is a good start, but it’s also somewhat tedious if you have many lists/features.
3. Pandas List to DataFrame With Multidimensional Lists
Think of multidimensional lists as lists of lists, or a list that has other lists as child elements. In Pandas, this means you can make a DataFrame from a list of lists, which is the input data format you’ll often encounter, as it’s easy to read and understand.
Let’s now see how you can make a DataFrame from a list of lists. Our outer list will have lists as child elements, and each child list will contain employee information, first name, last name and email address.
This multidimensional list is then used to construct a Pandas DataFrame:
employees = [
["Bob", "Doe", "[email protected]"],
["Mark", "Markson", "[email protected]"],
["Jane", "Swift", "[email protected]"],
["Patrick", "Johnson", "[email protected]"]
]
data = pd.DataFrame(
data=employees,
columns=["First Name", "Last Name", "Email"]
)
The DataFrame looks identical to the one from the previous section:
Neat, but what if your lists are inside a dictionary? Let’s cover that use case next.
4. Convert Dictionary of Lists to a Pandas DataFrame
Python dictionaries are used everywhere, but especially when working with Pandas. You can declare a dictionary that has a string for a key and list as a value. When a dictionary in this format is used to construct a Pandas DataFrame, the dictionary keys will be used as column names and dictionary values as values for each column at a given row.
This approach is by far the most common you’ll encounter, as it’s both easy to read and write:
employees = {
"First Name": ["Bob", "Mark", "Jane", "Patrick"],
"Last Name": ["Doe", "Markson", "Swift", "Johnson"],
"Email": ["[email protected]", "[email protected]", "[email protected]", "[email protected]"]
}
data = pd.DataFrame(employees)
Note how you don’t need to specify the column’s value inside pd.DataFrame() since column names are inferred from dictionary keys.
The resulting DataFrame is something you’re used to seeing by now:

5. List to Pandas DataFrame With Pandas from_records() Function
Pandas has a built-in method that allows you to convert a multidimensional Python list to DataFrame. It’s named from_records(), and it is a DataFrame specific method.
You don’t have to use it, since you can accomplish the same by passing a list of lists into a data argument when constructing a new Pandas DataFrame. But still, here’s an example in code:
employees = [
["Bob", "Doe", "[email protected]"],
["Mark", "Markson", "[email protected]"],
["Jane", "Swift", "[email protected]"],
["Patrick", "Johnson", "[email protected]"]
]
data = pd.DataFrame.from_records(employees)
data
The resulting DataFrame is correct, at least data-wise, but has no column names:
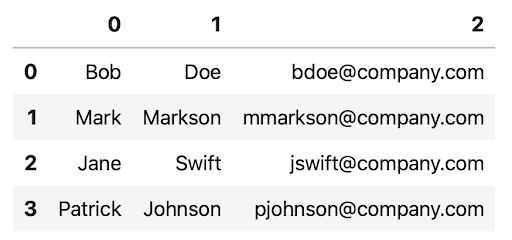
You need to explicitly supply the column names if you don’t want to use the default range index:
employees = [
["Bob", "Doe", "[email protected]"],
["Mark", "Markson", "[email protected]"],
["Jane", "Swift", "[email protected]"],
["Patrick", "Johnson", "[email protected]"]
]
data = pd.DataFrame.from_records(employees, columns=["First Name", "Last Name", "Email"])
data
You’ve now fixed the column names issue:
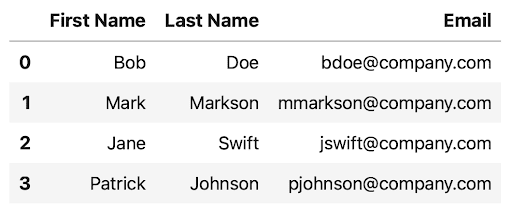
6. Pandas DataFrame From List With Index and Column Names
The `pd.DataFrame()` function allows you to create a DataFrame from a list while specifying both index and column names.
The list should contain sublists, where each sublist represents a single row of data. Then, you can define custom row labels using the `index` parameter and assign column names using the `columns` parameter.
Here’s an example: Employee email is used as index (row labels) and first/last name are shown as columns:
employees = [
["Bob", "Doe"],
["Mark", "Markson"],
["Jane", "Swift"],
["Patrick", "Johnson"]
]
index = [
"[email protected]",
"[email protected]",
"[email protected]",
"[email protected]"
]
data = pd.DataFrame(employees, index=index, columns=["First Name", "Last Name"])
data
The resulting DataFrame now has a custom index that can be used for searching:

Understanding Pandas List to DataFrame
You’ll often have to convert various data structures to Pandas DataFrames when working as a data analyst. Fortunately, Python lists are the most common ones.
This article showed you five ways to convert a Python list to Pandas DataFrame, regardless of the list dimensionality. A one-dimensional list translates to a single-column Pandas DataFrame, and a two-dimensional list means the DataFrame will have as many columns as there are elements in the first child list.
Frequently Asked Questions
How do you convert a list to a Pandas DataFrame?
The easiest method to convert a list to a Pandas DataFrame is to create a code snippet in which you declare a list of names in pd.dataframe, which then creates a Pandas DataFrame from it:
employees = ["Bob", "Mark", "Jane", "Patrick"]
data = pd.DataFrame(employees)
data
How do you convert multiple lists to Pandas DataFrame?
Python’s zip() function is used to iterate over two or more iterables at the same time. This code snippet declares two lists and uses zip() to produce a new list which is the combination of corresponding elements. This is a way to go if you want to make a Pandas DataFrame from two lists:
e_first_names = ["Bob", "Mark", "Jane", "Patrick"]
e_last_names = ["Doe", "Markson", "Swift", "Johnson"]
data = pd.DataFrame(
data=list(zip(e_first_names, e_last_names)),
columns=["First Name", "Last Name"]
)
data


