

Matrix factorization involves decomposing a large matrix RN*D into two lower rank matrices PN*K and QD*K such that the product of these smaller matrices approximates the original matrix as closely as possible:
P * QT ≈ R
But why is this decomposition necessary? To understand the importance of matrix factorization, we need to explore its application in recommender systems and collaborative filtering methods, where this technique plays an important role.
2 Types of Recommender Systems
- Content-based filtering: This method recommends items by analyzing the attributes of the items themselves, alongside user profiles and past interactions. For example, if a user has shown a preference for movies with a particular actor or genre, a content-based system would suggest similar movies based on those characteristics.
- Collaborative filtering: In contrast, collaborative filtering uses the preferences of a group of users with similar tastes. The underlying assumption is that users who have liked the same items in the past are likely to share preferences in the future. To recommend an item to a user, we can examine the items favored by users similar to that user and suggest those. The challenge here is identifying these similarities within the data, which matrix factorization can help with.
When Should You Use Matrix Factorization?
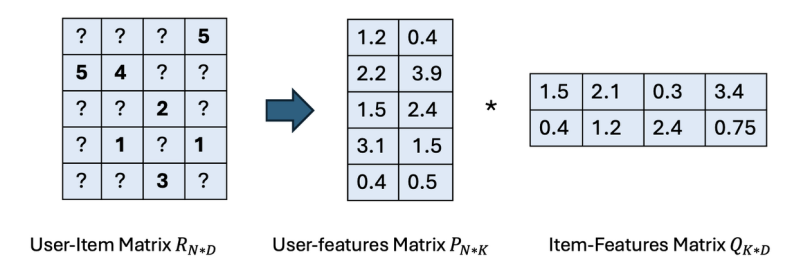
To illustrate the concept of matrix factorization, let’s consider a common example: a user-movie rating matrix.
Suppose we have a sparse matrix RN*D where N represents the number of users, and D is the number of movies (or items). Each entry rij in the matrix is an integer value that indicates the rating (on a scale of one to five) given by user i to movie j. Figure one illustrates an example of such a matrix.
After performing matrix factorization, we decompose this original matrix into two lower-rank matrices:
- PN*K, which represents a latent vector of size K for each user.
- QD*K, which represents a latent vector of size K for each movie.
The multiplication of these matrices (P * QT) approximates the original rating matrix R. Essentially, the dot product of the latent vector for user i and the latent vector for movie j yields a value that closely approximates the rating rij. Mathematically:
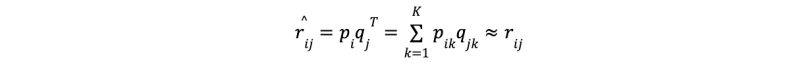
This process might seem straightforward, but it reveals a significant insight: latent features for both users and movies are learned automatically during the matrix factorization process. The matrices P and Q encode the interactions between users and movies based on these hidden factors.
For example, one latent feature could represent the movie’s genre — such as whether it’s a horror film — while on the user side, it could represent how much a user enjoys horror movies. The final predicted rating is essentially a weighted combination of these latent features.
Note, however, that these latent features are not explicitly defined; they emerge from the data during the factorization process, making them challenging to interpret directly.
Techniques of Matrix Factorization
To optimize the matrix factorization process, we aim to minimize the error between the original user-item matrix and its approximation through the factorized matrices. One common way to measure this error is by using the root mean square error between the known ratings in the original matrix and the predicted ratings from the matrix multiplication.
The cost function can be defined as:
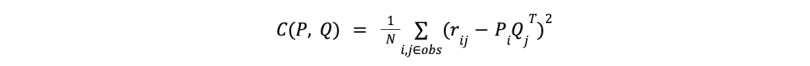
where N represents the number of observed ratings, and rij is the actual rating for user i and item j. The objective is to minimize this cost function by adjusting the matrices P and Q.
There are two common approaches to minimizing this cost function.
- Gradient descent: This method starts by initializing the values in the P and Q matrices randomly. Then, it iteratively updates these values by moving in the direction of the negative gradient of the cost function. By gradually reducing the error with each iteration, the algorithm eventually converges to a local optimum. Gradient descent is widely used in optimization problems, though the precise mathematical formulation is beyond the scope of this article
- Alternating least squares: In this approach, we iteratively solve for one matrix while keeping the other fixed. First, we fix P and optimize Q, and then we fix Q and optimize P. This alternating process continues until the cost function converges to a minimum.
Both methods aim to reduce the prediction error, allowing for more accurate recommendations in systems like collaborative filtering.
In addition to the standard matrix factorization techniques discussed above, several variations and related methods have been developed and explored by researchers over the years. Some of these are briefly summarized below.
- Non-negative matrix factorization: This variation of matrix factorization adds the constraint that none of the matrices R, P or Q can contain negative elements. NMF is especially useful in applications where non-negativity is inherent to the data, such as image processing, audio processing and spectral data analysis.
- Probabilistic matrix factorization: In this approach, a probabilistic framework is built around matrix factorization by employing Bayesian optimization techniques. By making assumptions about the distribution of the user-item matrix entries and defining prior distributions for matrices P and Q, PMF allows for posterior inference to find the values of P and Q matrices that would maximize the posterior distribution.
- Singular value decomposition: SVD is another matrix decomposition technique that differs from matrix factorization. It decomposes the original matrix into three matrices
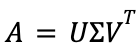 , where each matrix has distinct algebraic properties. SVD has numerous applications in image compression, recommender systems, principal component analysis, etc.
, where each matrix has distinct algebraic properties. SVD has numerous applications in image compression, recommender systems, principal component analysis, etc.
Best Practices for Implementing Matrix Factorization
When implementing a matrix factorization model, keep in mind these key considerations to ensure its effectiveness and reliability.
- Evaluation: Evaluate the model and confirm that the results meet expectations. In a recommendation system, a common approach is to use a holdout set of users. After training, you can compare the model’s predictions against real test examples in the holdout set. Professionals typically employ metrics like
Precision@KandRecall@Kto assess the model’s performance and determine how well it ranks relevant items. - Handling new users and items: In practical systems, new users and items are frequently added, causing the dimensions of the original matrices to change, which can invalidate the existing factorization. A common solution is to periodically re-run the factorization process to accommodate these new entries, ensuring the updated matrices reflect the newly added users and items.
- Regularization: To prevent overfitting and ensure the model generalizes well to unseen data, adding regularization terms to the objective function is a standard practice. Regularization helps in balancing the model’s complexity and performance, especially when dealing with sparse or limited data.
- Choosing the right dimension of latent features: Selecting the appropriate size for latent feature dimensions involves trade-offs. A higher dimension allows the model to capture more intricate patterns in the data, but at the cost of increased computational time. Conversely, a dimension size that is too small may lead to the model missing important patterns. In practice, it’s common to experiment with different dimension sizes and select the best one based on a balance between computational efficiency and model accuracy.
Applications of Matrix Factorization
One of the most important applications of matrix factorization is in recommender systems. In a typical user-movie interaction matrix, most of the entries are missing because not every user rates every movie.
This results in a sparse matrix. After applying matrix factorization, however, we obtain latent vectors for both users and items, enabling us to predict missing ratings.
For any unknown rating, we can compute the predicted rating by taking the dot product of the user’s latent vector pi and the movie’s latent vector qj. Mathematically, this is represented as:
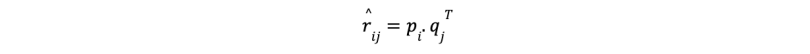
This scalar value ![]() provides the predicted rating for user i on movie j, even if the user has not previously rated that particular movie. Using these predicted ratings, we can recommend movies that a user is likely to enjoy but hasn't rated yet, offering a personalized recommendation experience.
provides the predicted rating for user i on movie j, even if the user has not previously rated that particular movie. Using these predicted ratings, we can recommend movies that a user is likely to enjoy but hasn't rated yet, offering a personalized recommendation experience.
In addition to its use in recommender systems, matrix factorization has several other practical applications. It’s commonly used for dimensionality reduction, where large data sets are simplified by breaking them into lower-rank matrices.
It also plays a key role in data and image compression, helping reduce the size of data sets and images while retaining essential features. Furthermore, matrix factorization is applied in natural language processing to generate word embeddings, which capture semantic relationships between words.
Benefits of Matrix Factorization
Matrix factorization offers several key advantages.
- Handling sparse and incomplete data: One of the primary benefits is its ability to effectively manage sparse and incomplete data sets, which are common in recommendation system applications. By decomposing the user-item matrix, matrix factorization can predict missing values, making it particularly useful when many users have interacted with only a small subset of items.
- Efficient dimensionality reduction: Matrix factorization acts as a powerful compression technique by reducing the dimensionality of the data. Instead of working with the original, potentially large user-item matrix, it generates two lower-rank matrices, significantly reducing the complexity of the recommendation system while still retaining useful information.
- Parallelization and scalability: Although the optimization process in matrix factorization can be time-consuming, especially for large data sets, many techniques have been developed to parallelize the process. Distributed computing approaches can be applied to make the training process faster and more efficient, allowing matrix factorization to scale effectively for large-scale recommendation systems.
Limitations of Matrix Factorization
Despite its effectiveness, matrix factorization has several key limitations.
- Cold start problem: One of the most significant challenges is the cold start problem, which arises when a new user or a new item is introduced to the system without sufficient interaction data. Matrix factorization relies heavily on past user-item interactions, and without enough historical data, it struggles to provide meaningful recommendations for new users or items.
- Being prone to overfitting: Matrix factorization can also be prone to overfitting, particularly when the dataset is small or sparse. In such cases, the model may over-optimize on the training data, leading to poor generalization when applied to unseen users or items. This can result in a model that performs well on the existing data but fails to provide accurate predictions in real-world scenarios.
- Lack of contextual information: Another limitation is that matrix factorization only considers user-item interaction data, ignoring other potentially useful contextual information. For instance, additional factors such as user demographics, location or time-based preferences could enhance recommendation accuracy. Matrix factorization, however, does not account for these factors, potentially limiting the relevance of its recommendations.
Frequently Asked Questions
What is matrix factorization versus matrix decomposition?
Matrix factorization and matrix decomposition both refer to the process of breaking down a matrix into two or more simpler matrices. Matrix decomposition, however, is a broader term that encompasses various decomposition techniques, such as SVD, LU decomposition, Cholesky decomposition, QR decomposition, etc. Each of these techniques imposes specific requirements on the resulting matrices, depending on the nature of the problem and the type of decomposition used.
What is content-based filtering?
Content-based filtering is a recommendation system approach that analyzes the attributes of items, along with user profiles and their past interactions, to provide personalized recommendations.
What is collaborative filtering?
Collaborative filtering is a recommendation system approach that uses the preferences of a group of users with similar tastes for doing recommendation. The underlying assumption is that users who have liked the same items in the past are likely to share preferences in the future.


